探索高效的数字ID生成方式,如何解决并发和死锁问题。本文介绍从雪花算法到自增ID优化的实践,分析了如何设计短小且连续的账号ID生成策略。针对ID生成瓶颈提出改进方案,并分享最终解决方案,避免数据库压力。
能不能生成尽量短点的数字ID?
背景
以前做过一个项目,里面有个需求是得给每个用户生成账号ID。最初我们用的是UUID,那种长字符串形式的ID,虽然功能强大,但存储和传输效率不高,性能差点不说,用户记起来也麻烦,大家都喜欢简短点的。
所以目标很明确:生成一套数字化的账号ID,而且尽量让它短点。
初步版本
最开始我们想到了雪花算法,大家熟悉的 twitter开源的snowflake算法。这个算法相当不错,生成的是64位的数字ID,支持分布式,稳定性和效率都没得说。
有兴趣的可以去看看详细分析:
看起来这个雪花算法完美无缺,但唯一问题就是,生成的64位ID太长了。大家的账号ID想尽量短些,主要原因大概有以下几点:
- 账号ID一般显示在个人设置里,暴露给用户,需要便于输入和记忆,能快速查询;
- 如果账号ID短且有序,能提高数据写入的效率。
所以咱们就想着怎么改进这个问题。
改进版本
这时候,我们想到的一个方案是利用数据库自增ID的特性。
先看看业务里的账号登录流程:
- 客户端上传第三方openid和token进行登录,登录服拿到openid后,得查查账号是否注册过
- 如果找到了账号ID,说明已经注册,直接用现有ID进行后续的登录操作
- 如果没有找到,就得创建一个新账号,插入到账号表中
- 新账号的ID生成方式,是通过一张专门的ID生成表来做的。
现在看看我们如何在mysql里存储这些账号信息:
账号表,accid就是我们说的数字账号。考虑到账号数目可能达到几千万,单表性能不行,我们就分了10张表,表结构如下:
CREATE TABLE `tbl_global_user_map_00` (
`account` varchar(32) NOT NULL,
`accid` bigint(20) NOT NULL,
`created_at` datetime DEFAULT NULL,
PRIMARY KEY (`account`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
账号ID生成表,表结构如下:
CREATE TABLE `tbl_accid` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`stub` char(1) NOT NULL DEFAULT '',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `UQE_tbl_accid_stub` (`stub`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
数据如下:
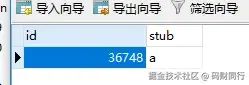
这张表只有一行数据,id是自增的,每次插入都会自动递增。它的原理是:
- id列设置为自增,这样每插入一行数据,id就会自动增长;
- 如果没有其他限制,这张表的数据会随着插入的次数越来越多,假如账号有几千万,表里就会有几千万行数据;
- 为避免数据过多,我们加了一列stub,并设置为
unique key,每次插入stub的值都是一样的(比如设置为’a’),确保整个表只有一行数据,id自动递增; - 这样每次插入时,如果直接用
insert into会报错,因为记录已经存在了,我们改用MySQL的扩展语句replace into来插入数据。
SQL语句如下:
REPLACE INTO tbl_accid(`stub`) VALUES('a');
效果是:
- 如果
stub='a'的记录不存在,就插入新记录; - 如果已经存在
stub='a'记录,就先删除,然后再插入新记录。因为删除时自增ID不变,新的记录插入时ID会继续递增。
大家可能会问,为什么不直接把自增ID放到账号表里?非得搞个单独的ID生成表?
主要是因为业务需要分表,假如账号表分了10张,ID生成的范围必须划分清楚,像我们每张表限定生成100万个ID,那这10张表的起始ID得分开,比如第1张表从1开始,第2张表从1000001开始,依此类推。
这种方法保证了ID短且连续,特别适合我们的需求,所以需要一个专门的ID生成表。
问题暴露
这个方案做完了,我就开心地去吃火锅唱歌了。
结果第二天,QA同事反馈,压力测试中系统偶尔返回了DB错误,错误日志上显示:
ERROR : Deadlock found when trying to get lock; try restarting transaction
很明显,这个方案引发了死锁问题。
google了一下,发现 REPLACE 在并发环境下有死锁问题,因为 replace 实际上是 delete + insert 组合操作,而 InnoDB 使用的是行级锁。详细原因有点复杂,相关资料如下:
- https://yq.aliyun.com/articles/41190
- https://techlog.cn/article/list/10183451#l
- http://blog.itpub.net/7728585/viewspace-2141409
有些博客给出的建议是:
避免在生产环境中使用
REPLACE INTO,改用普通的INSERT,并在插入失败时通过UPDATE进行处理。
为了验证是不是API的bug,我做了一个简单的压测:
mysqlslap -uroot -p --create-schema="db_global_200" --concurrency=2 --iterations=5 --number-of-queries=500 --query="replace_innodb.sql"
mysqlslap: Cannot run query REPLACE INTO tbl_yptest_innodb(`stub`) VALUES('a'); ERROR : Deadlock found when trying to get lock; try restarting transaction
结果显示,并发数为2时就有死锁问题。然后我换成 myisam 引擎,再压测,虽然没死锁问题,但更新效率低。于是我们决定放弃了这种MySQL自增ID的方案,转而寻找其他方法。
其他方案1
我们参考了美团技术团队的方案:
方案中提到,Flickr团队的方案使用多个MySQL服务器来提高可用性并减少单个服务器的并发压力。每次 replace into 串行执行,避免死锁。
不过,这种方案部署难度太高,尤其是登录服是多进程的,控制串行的难度大。这个方案只能被pass掉。
接着回到最初的想法,能不能将自增ID直接合并到账号表中,避免 replace 语句呢?
我们可以通过设置每个表的自增步长(比如每次自增10),让ID看起来间隔小而连续。
但遗憾的是,auto_increment_increment 和 auto_increment_offset 只能设置为全局或会话级别,不能在表级设置。设置了这两个变量,容易影响其他表,导致其他错误。
其他方案2
继续尝试其他方案。
如果只对账号表进行新增操作,考虑使用读写分离思想。通过将数据分布到10张表,控制每个表的写入量,减少表中自增ID的冲突。
这方案理论上可行,但运维复杂,需要数据迁移支持,维护成本较高,最终我们选择放弃。
其他方案3(最终方案)
我们最终采用了预申请ID的方式,每次批量申请一批ID,从而减少请求量和并发。
这种方式能有效减少ID浪费并避免ID空洞,完美契合我们之前的需求。
短ID方案细节
设计发号表 tbl_account_freeid:
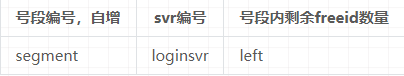
每个登录服要申请一批账号ID时,就在表中插入一行,规定每次申请1000个。通过 segment 和 left 控制剩余ID的数量。
以下是不同场景下的处理方式:
a) 初始没有数据时,服务器会查找对应的 segment,如果找不到就申请新的ID段。
b) 如果某些段的ID用完了,则申请新的区段。
c) 重新启动时,查询到号段后 left 设置为0,继续使用。
d) 登录服扩容时,新增实例会申请新的ID段。
这种方式有点像日志滚动,能够有效管理账号ID,防止浪费。
结尾
总结一下,以上是我们在短ID生成上的探索。最终的方案经过长时间的生产环境测试,运行稳定。如果有更好的方案,欢迎大家交流。
来源:juejin.cn/post/7393656776540291087