动态规划定义
任何数学递推公式都可以直接转换成递推算法,但是编译器常常不能正确对待递归算法。将递归重新写成非递归算法,让后者把些子问题的答案系统地记录在一个表内。利用这种方法的一种技巧叫做动态规划
注:由已知推未知就是递推,由未知推未知就是递归,这里说的数学递推公式有别与递推算法。具体解释如下: 如果数列{an}的第n项与它前一项或几项的关系可以用一个式子来表示,那么这个公式叫做这个数列的递推公式。
为什么编译器常常不能正确对待递归?
递归4条基本法则
1、 基准情形。必须有某些基准情形,它无需递归就能解出。
2、 不断推进。对于那些递归求解的步骤,每一次递归调用都必须要使情况朝一种
3、 设计法则。假设所有的递归调用都能运行。
4、 合成效益法则(compound interest rule)。在求解一个问题的实例时,切勿在不同的递归调用中做重复的操作。 递归的4条法则中,效率低下的递归实现经常触犯第4条法则,即合成效益法则,也是编译器通常无法正确对待递归的原因。下面举例说明。
以求斐波那契数为例说明
问题说明
有通项公式 f(n)=f(n-1)+f(n-2); f(0)=f(1)=1;求任意n对应的f(n)
注意:目前有的编译器可以优化尾递归
递归解法及存在的问题
/**
* 递归实现违反合成效益法则
* */
public static int fib(int n){
if(n<=1){
return 1;
}else{
return fib(n-1)+fib(n-2);
}
}
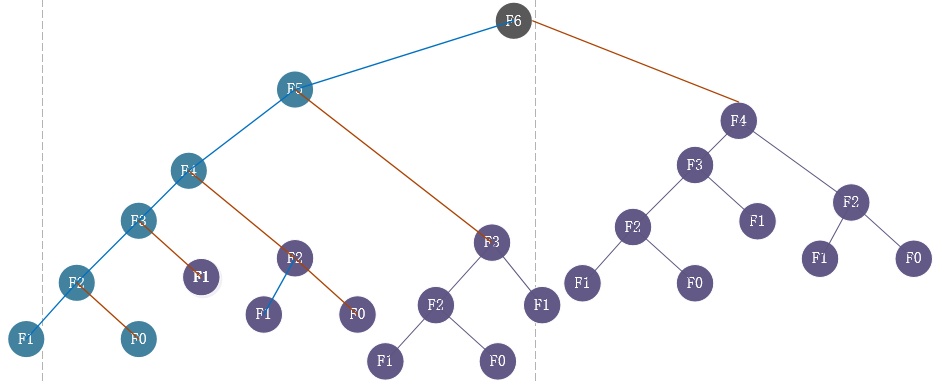
以求f6为例,计算f6需要计算f5和f4,而算f5是有需要计算f4+f3,则必定有重复计算的部分。具体详细见下图,(下图紫色部分都是多余计算)
分析
由于计算F(N)只需要知道F(N-1)和F(N-2),因此我们只需要保留最近算出的两个斐波那契数,并从f(2)开始一直计算的f(n)即可。
代码实现
/**
* 动态规划版本,保证没有多余的计算,
* 以last 保存f(i-1)的值,nextToLast保存f(i-2)
* answer 保存f(i)的值
* */
public static int fibonacci(int n){
if(n<=1){
return 1;
}
int last=1;
int nextToLast=1;
int answer=1;
for(int i=2;i<=n;i++){
answer=last+nextToLast;
nextToLast=last;
last=answer;
}
return answer;
}
小试牛刀解背包问题
问题说明
假定背包的最大容量为W,N件物品,每件物品都有自己的价值val和重量wt,将物品放入背包中使得背包内物品的总价值最大(val的和最大)。
分析
临时背包总价值=Max{选取当前项背包总价值,不选取当前项背包总价值},转换为数学公式为:
选取当前项时, 临时背包总价值=val[item-1]+V[item-1][weight-wt[item-1]]
不选取当前项,临时背包总价值= V[item-1][weight]
V[item][weight]=Math.max (val[item-1]+V[item-1][weight-wt[item-1]], V[item-1][weight]);
进过上步骤分析,我们仅需保留以item为行,以权重weight为列的二维数组即可。具体实现如下:
代码实现(非自实现)
/**
* @param val 权重数组
* @param wt 重量数组
* @param W 总权重
* @return 背包中使得背包内物品的总价值最大时的重量
*/
public static int knapsack(int val[], int wt[], int W) {
//物品数量总和
int N = wt.length;
//创建一个二维数组
//行最多存储N个物品,列最多为总权重W,下边N+1和W+1是保证从1开始
int[][] V = new int[N + 1][W + 1];
//将行为 0或者列为0的值,都设置为0
for (int col = 0; col <= W; col++) {
V[0][col] = 0;
}
for (int row = 0; row <= N; row++) {
V[row][0] = 0;
}
//从1开始遍历N个物品
for (int item=1;item<=N;item++){
//一行一行的填充数据
for (int weight=1;weight<=W;weight++){
if (wt[item-1]<=weight){
//选取(当前项值+之前项去掉当前项权重的值)与不取当前项的值得最大者
V[item][weight]=Math.max (val[item-1]+V[item-1][weight-wt[item-1]], V[item-1][weight]);
}else {//不选取当前项,以之前项代替
V[item][weight]=V[item-1][weight];
}
}
}
//打印最终矩阵
for (int[] rows : V) {
for (int col : rows) {
System.out.format("%5d", col);
}
System.out.println();
}
//返回结果
return V[N][W];
}
总结
1、 编译器一般不能很好的处理递归,尤其是违反合成效益法则的递归
2、 动态规划需要分析,其重点在于以适用的数据结构保持递归步骤中的中间值。
3、 是否需要将递归转换为非递归需要以实际项目的情况,酌情考虑。